Automating Stem Separation with Colab and Demucs
Lately, I have been getting back into music production and needed a way to find, separate, and prepare audio. I built a pipeline that takes a YouTube link (or raw mp3 files), extracts the highest quality audio and uses a neural network to split it into separate stems like drums, bass and vocals.
Everything runs on Google Colab, connected directly to my Google Drive space where the files land permanently. I expose the control panel through an ngrok tunnel, allowing me to reach the server from my phone. It operates strictly as a private cloud tool I spin up when I need it.
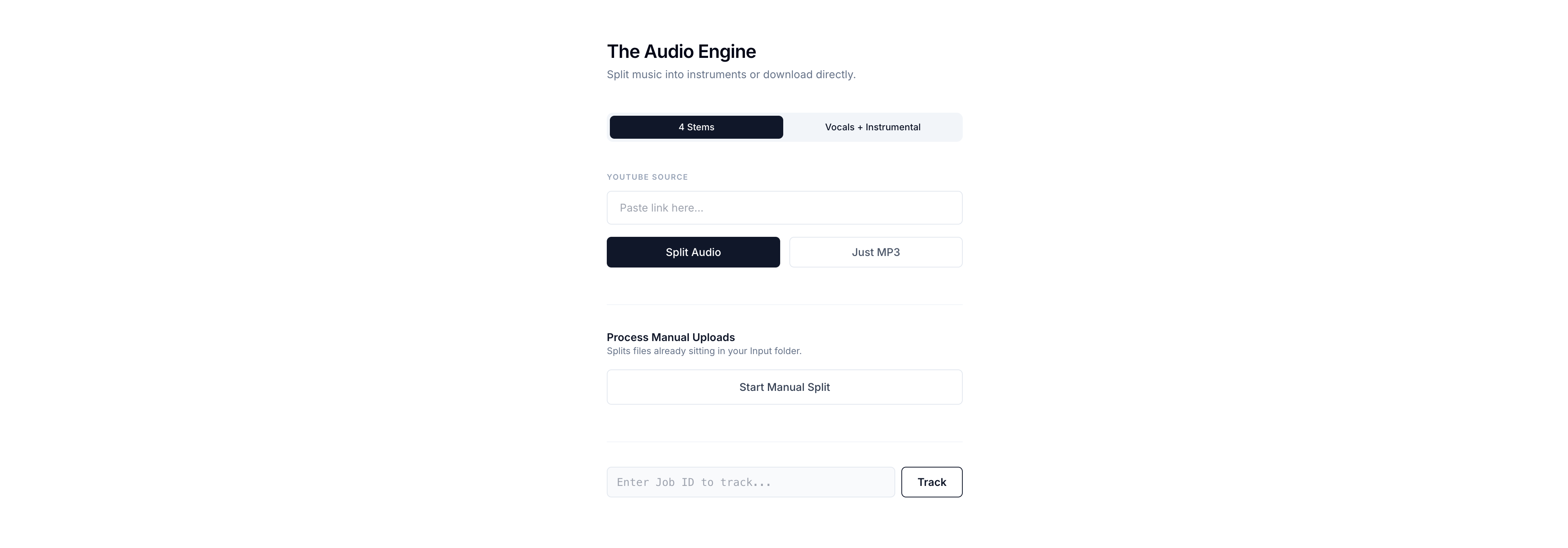
The Audio Engine
Tool
A minimal audio engine built on Google Colab that automates YouTube retrieval and neural stem separation directly to Google Drive.
The Setup and Architecture
The architecture is deliberately disjointed. My phone acts as the control surface, Google Colab provides the heavy GPU compute and Google Drive serves as the permanent storage layer.
To make this run on Colab’s dynamic PyTorch environment, I bypass strict dependency constraints. I install yt-dlp for extraction and pull demucs directly from its repository to ensure compatibility.
!pip install -q torch torchaudio torchvision
!pip install -q --no-deps git+https://github.com/adefossez/demucs
!pip install -q dora-search julius lameenc openunmix yt-dlp flask pyngrok
Handling paths and secrets entirely within the Colab environment prevents hardcoding sensitive tokens. The script pulls API keys and Drive paths dynamically from Colab's internal userdata vault.
from google.colab import userdata
from pathlib import Path
from dataclasses import dataclass, field
def get_secret_path(key: str) -> Path:
"""Retrieves a secret and converts to Path, failing with a clear error if missing."""
value = userdata.get(key)
if value is None:
raise ValueError(f"❌ Secret '{key}' is missing! Please add it in the Secrets tab and enable notebook access.")
return Path(value)
@dataclass
class DemucsConfig:
model: str = "htdemucs_ft"
mp3_bitrate: int = 320
raw_audio_input_path: Path = field(default_factory=lambda: get_secret_path('DEMUCS_IN_PATH'))
separated_stems_output_path: Path = field(default_factory=lambda: get_secret_path('DEMUCS_OUT_PATH'))
youtube_downloads_path: Path = field(default_factory=lambda: get_secret_path('YOUTUBE_OUT_PATH'))
cfg = DemucsConfig()
Retrieval
The pipeline starts with source material. I paste a YouTube link into the web interface, and the system uses yt-dlp to fetch the highest available audio stream, immediately converting it to a 320kbps MP3 inside a designated Google Drive folder.
import subprocess as sp
def download_youtube_audio(url: str, download_folder: Path):
download_folder.mkdir(parents=True, exist_ok=True)
filename_template = str(download_folder / "%(title)s.%(ext)s")
cmd = [
"yt-dlp", "--no-playlist", "-f", "bestaudio", "-x",
"--audio-format", "mp3", "--audio-quality", "0",
"-o", filename_template, url
]
sp.run(cmd, check=True)
Separation
Once the audio lands in Drive, the system triggers the Demucs deep learning model. Specifically, it uses the htdemucs_ft configuration, which analyzes frequency patterns and physically isolates the track into precise stems. I execute it as a subprocess strictly to force GPU acceleration (-d cuda), cutting processing time from minutes to seconds.
I decide the separation mode upfront: either a full four-stem split (vocals, drums, bass, other) or a simple two-stem track for when I only need a clean instrumental.
def run_demucs_separation(input_dir: Path, output_dir: Path, mode: str = "4stems"):
audio_files = [f for f in input_dir.iterdir() if f.suffix.lower() in [".mp3", ".wav"]]
cmd = ["python3", "-m", "demucs.separate", "-o", str(output_dir), "-n", cfg.model, "-d", "cuda", "--mp3", f"--mp3-bitrate={cfg.mp3_bitrate}"]
if mode != "4stems":
cmd.append(f"--two-stems={mode}")
cmd.extend([str(f) for f in audio_files])
sp.run(cmd, check=True)
Background Threading and Mobile Access
Because separation is a heavy machine learning task, running it synchronously would instantly freeze the Flask control panel. To solve this, I handle all jobs via background threading. The UI immediately returns a Job ID, while the GPU heavily processes the audio in the background. I expose this local Flask server to the internet using an ngrok tunnel. This gives me a public URL I can open on my phone to queue jobs while I am away from my computer.
from flask import Flask, request
from pyngrok import ngrok
import threading
import uuid
import shutil
app = Flask(__name__)
active_jobs = {}
@app.route("/process_url")
def process_url():
url = request.args.get("url")
mode = request.args.get("mode", "4stems")
job_id = str(uuid.uuid4())
active_jobs[job_id] = "queued"
def worker():
temp_folder = Path(f"tmp_{job_id}")
active_jobs[job_id] = "downloading"
download_youtube_audio(url, temp_folder)
active_jobs[job_id] = "separating"
run_demucs_separation(temp_folder, cfg.separated_stems_output_path, mode)
shutil.rmtree(temp_folder)
active_jobs[job_id] = "completed"
threading.Thread(target=worker).start()
return {"job_id": job_id}
if __name__ == "__main__":
ngrok.set_auth_token(userdata.get('NGROK_AUTH_TOKEN'))
tunnel = ngrok.connect(5000, domain=userdata.get('NGROK_DOMAIN'))
print(f"Public URL: {tunnel.public_url}")
app.run(port=5000)
Manual Control
Not everything comes from YouTube. If I drop arbitrary WAV or FLAC files directly into a designated Input folder in Google Drive, I can hit a separate /separate_manual endpoint on the UI. The pipeline scans the directory and processes the manually injected queue automatically.
Limitation
Google Colab sessions shut down automatically after periods of inactivity. For this workflow, that limitation becomes a primary feature.
I start the instance, process the audio I need, and shut the session down. The raw material and processed stems remain safely stored in Google Drive. I built exactly what I needed: a pipeline leveraging free cloud GPUs that executes heavy machine learning tasks and cleanly disappears.