The Audio Engine
I’m still not sure if I should publish this, but I’ll show what I built and you can decide if it’s worth using.
Lately I’ve been getting back into music, mostly how I find and prepare audio. It’s a gray area. I use material from YouTube, and I’m not fully sure what can be reused. If you plan to do this, check that part yourself.
What I can explain is the setup.
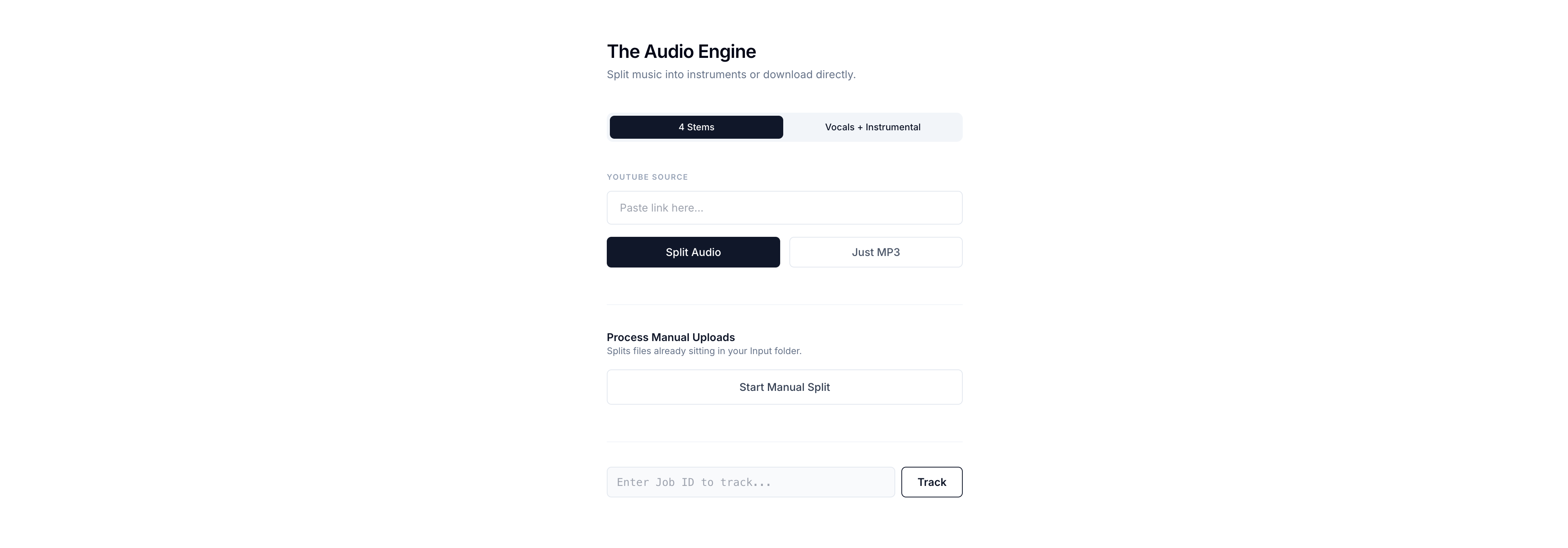
I built a small pipeline that takes audio and splits it into stems like drums, bass, vocals and everything else. I didn’t turn it into an app and I didn’t pay for any tools.
Everything runs in one place on Google Colab. It’s connected to my Google Drive so files stay there and I expose it through an ngrok tunnel so I can reach it from any device. In practice, it feels like a small private tool I turn on when I need it.
The Audio Engine
Tool
A minimal audio engine built on Google Colab that automates YouTube retrieval and neural stem separation directly to Google Drive.
The setup
The interface is simple. No heavy frontend, just a clean control panel styled with Tailwind. It works well on mobile because most of the time I just trigger a job from my phone and check the results later in Drive.
Behind that, the system handles paths and secrets through Colab. Tokens and file paths are not hardcoded. The server runs on Flask, but it doesn’t freeze when work starts. Jobs run in background threads. When I start a task, I get a Job ID right away and the processing continues on the GPU without blocking the interface.
How it works
The system does three things.
First, retrieval. I paste a YouTube link and the system uses yt-dlp to fetch the best audio and save it as a 320kbps MP3 in Drive.
Second, separation. It runs the Demucs model, htdemucs_ft. It analyzes frequency patterns and splits the track into separate parts.
Third, modes. I can choose how the track is split. Either four stems, vocals, drums, bass and other, or a simple vocals and instrumental version when I only need a clean backing track.
Manual control and status
There’s also a manual option. If I drop files into an Input folder in Drive, I can trigger processing with one click. The system scans the folder, finds supported formats like mp3, wav, and flac, and processes them.
To track progress, I added a status check. I can paste the Job ID and see the current state, queued, downloading, separating, or completed.
Conclusion
Colab sessions stop after a while since it’s not meant to run all the time. For me, that’s fine. I start it, process what I need and shut it down.
From the outside, it might look like a small service. In reality, it’s just free tools connected in a simple way.
The goal was clear. Use what’s already there, connect it properly, and get solid results without building more than needed. I didn’t want a product. I wanted something that works when I need it.